


Para melhor auxiliar os usuários humanos enquanto eles realizam as tarefas diárias, os robôs devem ser capazes de entender suas dúvidas, respondê-las e realizar ações de acordo. Em outras palavras, eles devem ser capazes de gerar e executar com flexibilidade ações que estejam alinhadas com as instruções verbais do usuário.
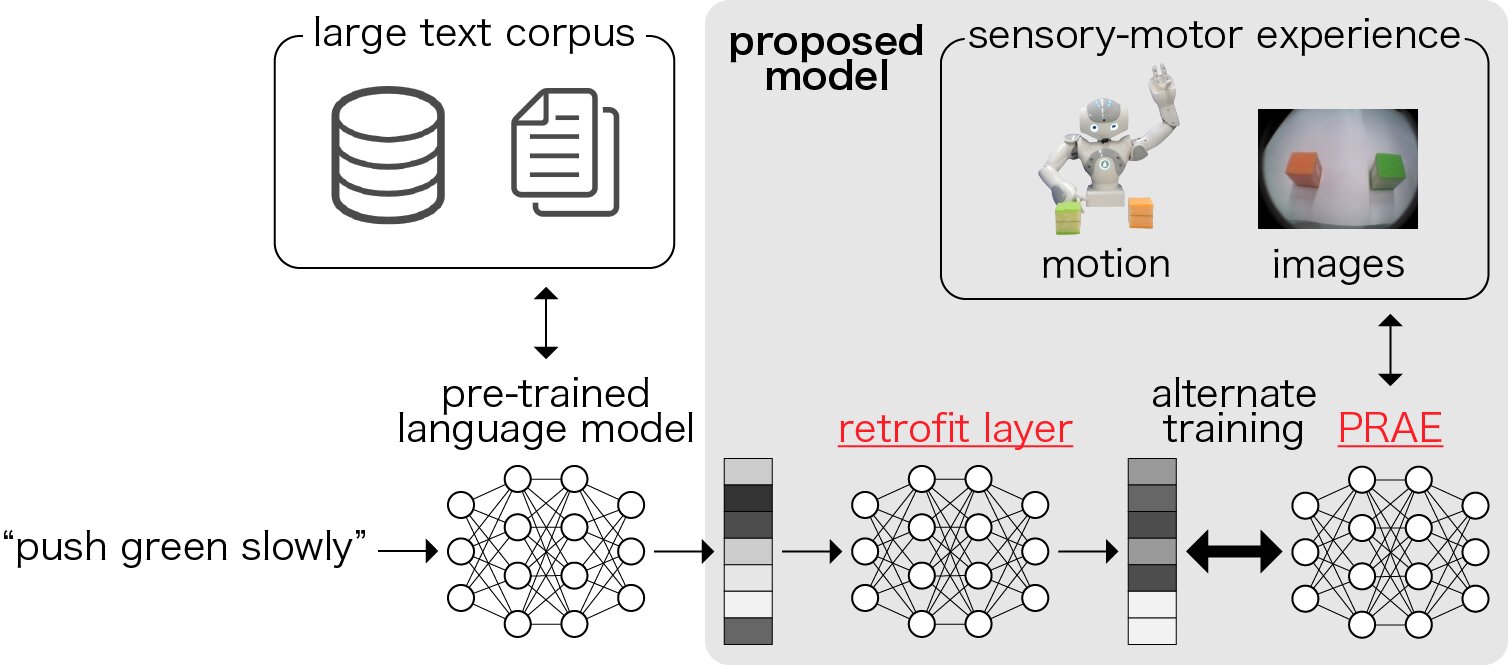
Para entender as instruções de um usuário e agir de acordo, os sistemas robóticos devem ser capazes de fazer associações entre expressões linguísticas, ações e ambientes. As redes neurais profundas provaram ser particularmente boas na aquisição de representações de expressões linguísticas, mas normalmente precisam ser treinadas em grandes conjuntos de dados, incluindo ações de robôs, descrições linguísticas e informações sobre diferentes ambientes.
Pesquisadores da Universidade Waseda em Tóquio desenvolveram recentemente uma rede neural profunda que pode adquirir representações fundamentadas das ações do robô e descrições linguísticas dessas ações. A técnica que eles criaram, apresentada em um artigo publicado na IEEE Robotics and Automation Letters, poderia ser usada para aumentar a capacidade dos robôs de executar ações alinhadas com as instruções verbais do usuário.
“Estamos lidando com o problema de como integrar símbolos e o mundo real, o ‘problema de aterramento de símbolos'”, disse Tetsuya Ogata, um dos pesquisadores que realizaram o estudo, ao TechXplore. “Já publicamos vários artigos relacionados a esse problema com robôs e redes neurais.”
O novo modelo baseado em rede neural profunda pode adquirir representações vetoriais de palavras, incluindo descrições do significado das ações. Usando essas representações, ele pode gerar ações de robô adequadas para palavras individuais, mesmo se essas palavras forem desconhecidas (ou seja, se não estiverem incluídas no conjunto de dados de treinamento inicial).
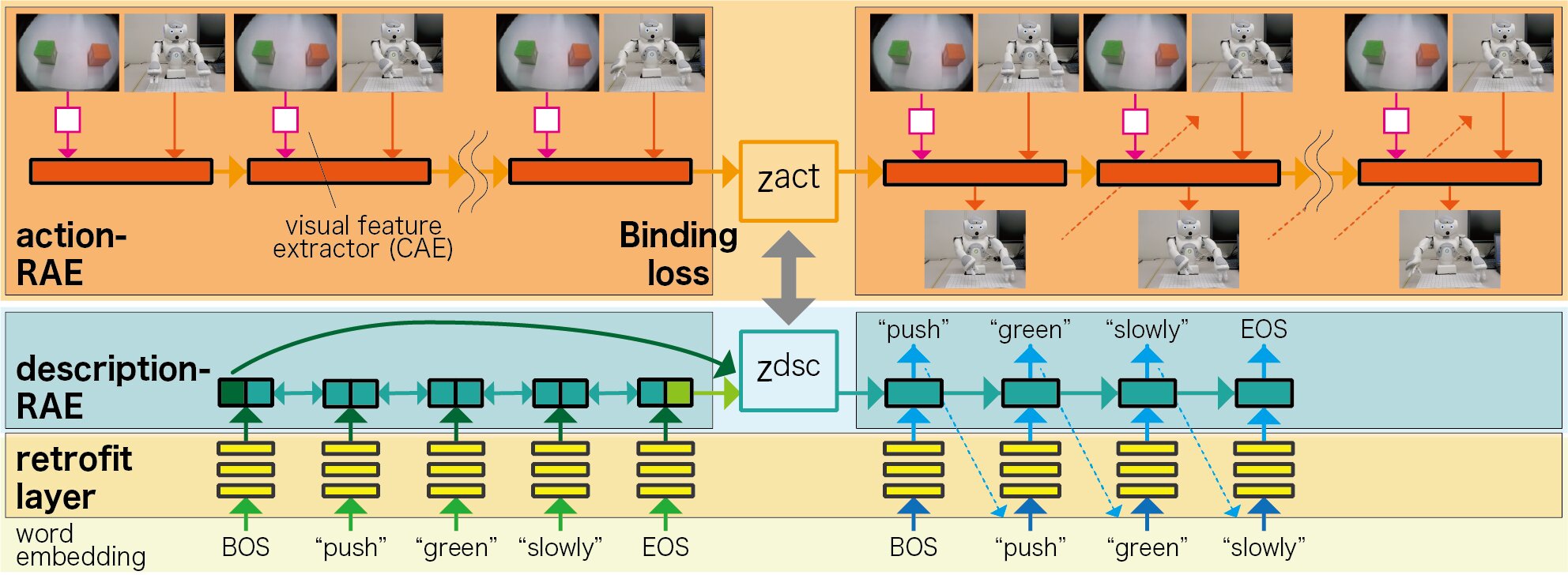
“Especificamente, convertemos os vetores de palavras do modelo de aprendizado profundo pré-treinado com um corpus de texto em diferentes vetores de palavras que podem ser usados para descrever os comportamentos de um robô”, explicou Ogata. “Na aprendizagem normal de corpus de linguagem, vetores de similaridade são dados a palavras que aparecem em contextos semelhantes, de modo que o significado da ação apropriada não pode ser obtido. Por exemplo, ‘rápido’ e ‘lentamente’ têm representações vetoriais semelhantes na linguagem, mas eles têm significados opostos na ação real. Nosso método resolve esse problema. ”
Ogata e seus colegas treinaram a camada de retrofit de seu modelo e seu modelo de tradução bidirecional alternadamente. Este processo de treinamento permite que seu modelo transforme os embeddings de palavras pré-treinados e os adapte aos pares existentes de ações e descrições associadas.
“Nosso estudo sugere que a aprendizagem de integração de linguagem e ação pode permitir aquisições de representação vetorial que reflitam os significados do mundo real de advérbios e verbos, incluindo palavras desconhecidas, que são difíceis de adquirir em modelos de aprendizagem profunda usando apenas um grande corpus de texto,” Ogata disse.
Nas avaliações iniciais, a técnica de aprendizado profundo alcançou resultados altamente promissores, pois pode gerar ações do robô a partir de palavras nunca antes vistas (ou seja, palavras que não foram emparelhadas com ações correspondentes no conjunto de dados usado para treinar o modelo). No futuro, o novo modelo pode permitir o desenvolvimento de robôs que entendem melhor as instruções humanas e agem de acordo.
“Este estudo foi o primeiro passo de nossa pesquisa nessa direção e ainda há muito espaço para melhorias na vinculação de linguagem e comportamento”, disse Ogata. “Por exemplo, ainda é difícil converter algumas palavras. Nesta pesquisa, o número de movimentos do robô era pequeno, então gostaríamos de aumentar a flexibilidade do robô para lidar com frases mais complexas no futuro.”
Publicado em 15/05/2021 17h27
Artigo original:
Estudo original: