



DOI: 10.48550/arXiv.2309.03157
Credibilidade: 898
#UAVs
Os veículos aéreos não tripulados (UAV), vulgarmente conhecidos como drones, já se revelaram inestimáveis para resolver uma vasta gama de problemas do mundo real. Por exemplo, eles podem ajudar humanos em entregas, monitoramento ambiental, produção de filmes e missões de busca e salvamento.
Embora o desempenho dos UAV tenha melhorado consideravelmente ao longo da última década, muitos deles ainda têm baterias de duração relativamente curta, pelo que podem ficar sem energia e parar de funcionar antes de completarem uma missão. Muitos estudos recentes na área da robótica têm assim como objetivo melhorar a vida útil das baterias destes sistemas, ao mesmo tempo que desenvolvem técnicas computacionais que lhes permitem enfrentar missões e planear as suas rotas da forma mais eficiente possível.
Pesquisadores da Universidade Técnica de Munique (TUM) e da Universidade da Califórnia em Berkeley (UC Berkeley) têm tentado desenvolver melhores soluções para lidar com o problema de pesquisa comumente subjacente, conhecido como planejamento de caminho de cobertura (CPP). Em um artigo recente pré-publicado no arXiv, eles introduziram uma nova ferramenta baseada em aprendizado por reforço que otimiza as trajetórias dos UAVs ao longo de uma missão inteira, incluindo visitas a estações de carregamento quando a bateria está fraca.
“As raízes desta pesquisa remontam a 2016, quando iniciamos nossa pesquisa sobre “UAVs movidos a energia solar e de longa duração”, disse Marco Caccamo, um dos pesquisadores que realizou o estudo, ao Tech Xplore.
“Anos após o início desta pesquisa, ficou claro que o CPP é um componente chave para permitir a implantação de UAV em vários domínios de aplicação, como agricultura digital, missões de busca e salvamento, vigilância e muitos outros. É um problema complexo para resolver tantos fatores precisam ser considerados, incluindo prevenção de colisões, campo de visão da câmera e vida útil da bateria. Isso nos motivou a investigar a aprendizagem por reforço como uma solução potencial para incorporar todos esses fatores.”
Em seus trabalhos anteriores, Caccamo e seus colegas tentaram resolver versões mais simples do problema CPP usando aprendizagem por reforço. Especificamente, consideraram um cenário em que um UAV tinha restrições de bateria e tinha que cumprir uma missão dentro de um período de tempo limitado (ou seja, antes que a bateria acabasse).
Nesse cenário, os pesquisadores usaram o aprendizado por reforço para permitir que o UAV concluísse o máximo de uma missão ou se movesse pelo máximo de espaço possível com uma única carga de bateria. Ou seja, o robô não poderia interromper a missão para recarregar sua bateria, reiniciando posteriormente de onde parou antes.
“Além disso, o agente teve que aprender as restrições de segurança, ou seja, evitar colisões e limites de bateria, que geraram trajetórias seguras na maioria das vezes, mas não sempre”, explicou Alberto Sangiovanni-Vincentelli. “Em nosso novo artigo, queríamos estender o problema do CPP, permitindo que o agente recarregasse para que os UAVs considerados neste modelo pudessem cobrir um espaço muito maior. Além disso, queríamos garantir que o agente não violasse as restrições de segurança, uma requisito óbvio em um cenário do mundo real.”
Uma vantagem importante das abordagens de aprendizagem por reforço é que tendem a generalizar bem em diferentes casos e situações. Isso significa que, após o treinamento com métodos de aprendizagem por reforço, os modelos muitas vezes podem enfrentar problemas e cenários que não encontraram antes.
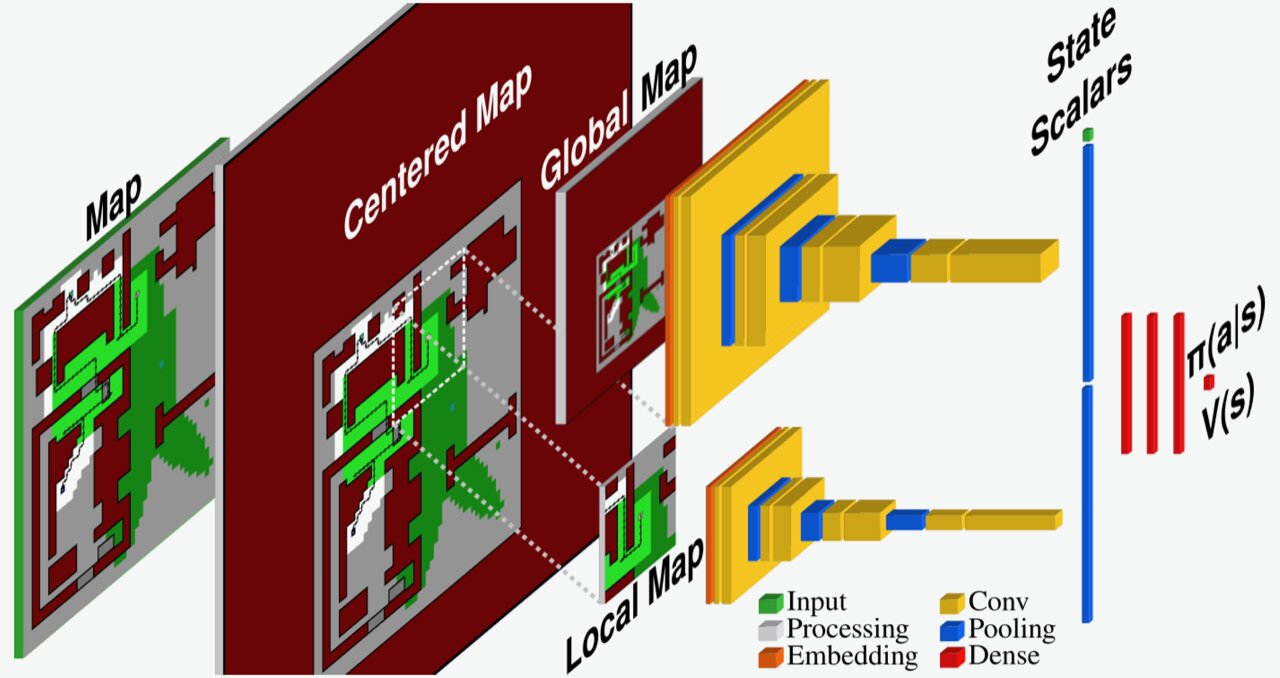
Essa capacidade de generalizar depende muito de como o problema é apresentado ao modelo. Especificamente, o modelo de aprendizagem profunda deve ser capaz de analisar a situação em questão de uma forma estruturada, por exemplo, na forma de um mapa.
Para enfrentar o novo cenário CPP considerado em seu artigo, Caccamo, Sangiovanni-Vincentelli e seus colegas desenvolveram um novo modelo baseado em aprendizagem por reforço. Este modelo essencialmente observa e processa o ambiente em que um UAV se move, que é representado como um mapa, e o centraliza em torno de sua posição.
Posteriormente, o modelo comprime todo o “mapa centralizado” em um mapa global com resolução mais baixa e um mapa local de resolução total mostrando apenas a vizinhança imediata do robô. Esses dois mapas são então analisados para otimizar as trajetórias do UAV e decidir suas ações futuras.
“Através de nosso pipeline exclusivo de processamento de mapas, o agente é capaz de extrair as informações necessárias para resolver o problema de cobertura para cenários invisíveis”, disse Mirco Theile. “Além disso, para garantir que o agente não viola as restrições de segurança, definimos um modelo de segurança que determina quais das ações possíveis são seguras e quais não são. Através de uma abordagem de mascaramento de ação, aproveitamos este modelo de segurança definindo um conjunto de ações seguras em todas as situações que o agente encontra e deixando o agente escolher a melhor ação entre as seguras”.
Os pesquisadores avaliaram sua nova ferramenta de otimização em uma série de testes iniciais e descobriram que ela superava significativamente um método de planejamento de trajetória de base. Notavelmente, o seu modelo generalizou-se bem em diferentes zonas-alvo e mapas conhecidos, e também poderia abordar alguns cenários com mapas invisíveis.
“O problema do CPP com recarga é significativamente mais desafiador do que aquele sem recarga, pois se estende por um horizonte de tempo muito mais longo”, disse Theile. “O agente precisa tomar decisões de planejamento de longo prazo, por exemplo, decidir quais zonas-alvo deve cobrir agora e quais pode cobrir quando retornar para recarregar. Mostramos que um agente com observações baseadas em mapas, mascaramento de ação baseado em modelo de segurança , e fatores adicionais, como programação de fatores de desconto e histórico de posições, podem tomar decisões sólidas de longo prazo.”
A nova abordagem baseada em aprendizagem por reforço introduzida por esta equipe de pesquisa garante a segurança de um UAV durante a operação, pois apenas permite ao agente selecionar trajetórias e ações seguras. Ao mesmo tempo, poderia melhorar a capacidade dos UAV de completar missões de forma eficaz, otimizando as suas trajetórias para pontos de interesse, locais-alvo e estações de carregamento quando a bateria estiver fraca.
Este estudo recente poderia inspirar o desenvolvimento de métodos semelhantes para resolver problemas relacionados ao CPP. O código e o software da equipe estão disponíveis publicamente no GitHub, portanto, outras equipes em todo o mundo poderão em breve implementá-los e testá-los em seus UAVs.
“Este artigo e nosso trabalho anterior resolveram o problema do CPP em um mundo de grade discreta”, acrescentou Theile. “Para trabalhos futuros, para nos aproximarmos das aplicações do mundo real, investigaremos como trazer os elementos cruciais, observações baseadas em mapas e mascaramento de ações de segurança para o mundo contínuo. Resolver o problema no espaço contínuo permitirá sua implantação em condições reais. missões mundiais, como a agricultura inteligente ou a monitorização ambiental, que esperamos que possam ter um grande impacto.”
Publicado em 01/10/2023 15h03
Artigo original:
Estudo original: