



Modelos modernos de aprendizado de máquina, como redes neurais, são frequentemente chamados de “caixas pretas” porque são tão complexos que mesmo os pesquisadores que os projetam não conseguem entender completamente como fazem previsões.
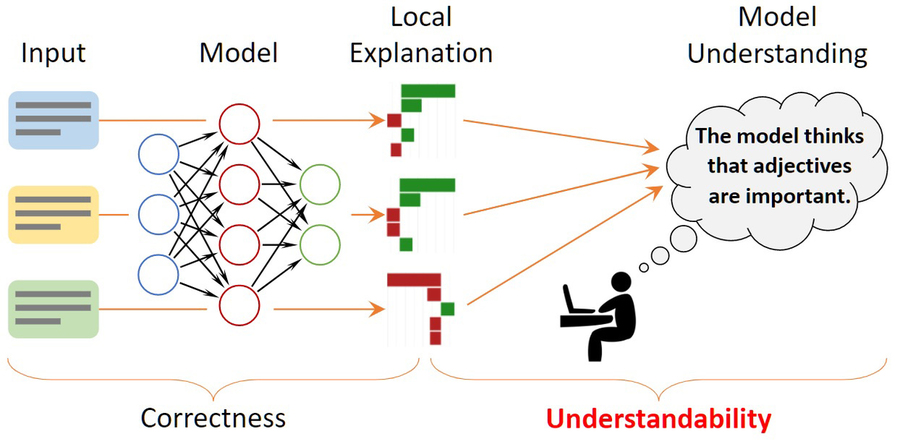
Para fornecer alguns insights, os pesquisadores usam métodos de explicação que procuram descrever decisões de modelos individuais. Por exemplo, eles podem destacar palavras em uma crítica de filme que influenciaram a decisão do modelo de que a crítica foi positiva.
Mas esses métodos de explicação não servem para nada se os humanos não puderem entendê-los facilmente ou até mesmo interpretá-los mal. Assim, os pesquisadores do MIT criaram uma estrutura matemática para quantificar e avaliar formalmente a compreensibilidade das explicações para modelos de aprendizado de máquina. Isso pode ajudar a identificar insights sobre o comportamento do modelo que podem ser perdidos se o pesquisador estiver avaliando apenas algumas explicações individuais para tentar entender todo o modelo.
“Com essa estrutura, podemos ter uma visão muito clara não apenas do que sabemos sobre o modelo a partir dessas explicações locais, mas, mais importante, do que não sabemos sobre ele”, diz Yilun Zhou, graduado em engenharia elétrica e ciência da computação. estudante do Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL) e autor principal de um artigo apresentando este framework.
Os coautores de Zhou incluem Marco Tulio Ribeiro, pesquisador sênior da Microsoft Research, e a autora sênior Julie Shah, professora de aeronáutica e astronáutica e diretora do Interactive Robotics Group no CSAIL. A pesquisa será apresentada na Conferência do Capítulo Norte-Americano da Association for Computational Linguistics.
Créditos:Imagem: Cortesia dos pesquisadores
Entendendo as explicações locais
Uma maneira de entender um modelo de aprendizado de máquina é encontrar outro modelo que imite suas previsões, mas use padrões de raciocínio transparentes. No entanto, os modelos recentes de redes neurais são tão complexos que essa técnica geralmente falha. Em vez disso, os pesquisadores recorrem ao uso de explicações locais que se concentram em entradas individuais. Muitas vezes, essas explicações destacam palavras no texto para significar sua importância para uma previsão feita pelo modelo.
Implicitamente, as pessoas generalizam essas explicações locais para o comportamento geral do modelo. Alguém pode ver que um método de explicação local destacou palavras positivas (como “memorável”, “impecável” ou “encantador”) como sendo as mais influentes quando o modelo decidiu que uma crítica de filme tinha um sentimento positivo. Eles provavelmente assumirão que todas as palavras positivas fazem contribuições positivas para as previsões de um modelo, mas isso nem sempre pode ser o caso, diz Zhou.
Os pesquisadores desenvolveram uma estrutura, conhecida como ExSum (abreviação de resumo de explicação), que formaliza esses tipos de declarações em regras que podem ser testadas usando métricas quantificáveis. O ExSum avalia uma regra em um conjunto de dados inteiro, em vez de apenas na instância única para a qual ela foi construída.
Usando uma interface gráfica de usuário, um indivíduo escreve regras que podem ser ajustadas, ajustadas e avaliadas. Por exemplo, ao estudar um modelo que aprende a classificar críticas de filmes como positivas ou negativas, pode-se escrever uma regra que diga “palavras de negação têm saliência negativa”, o que significa que palavras como “não”, “não” e “nada”. contribuem negativamente para o sentimento das resenhas de filmes.
Usando o ExSum, o usuário pode ver se essa regra se mantém usando três métricas específicas: cobertura, validade e nitidez. A cobertura mede quão amplamente aplicável é a regra em todo o conjunto de dados. A validade destaca a porcentagem de exemplos individuais que concordam com a regra. A nitidez descreve a precisão da regra; uma regra altamente válida pode ser tão genérica que não é útil para entender o modelo.
Testando suposições
Se um pesquisador busca uma compreensão mais profunda de como seu modelo está se comportando, ele pode usar o ExSum para testar suposições específicas, diz Zhou.
Se ela suspeitar que seu modelo é discriminatório em termos de gênero, ela pode criar regras para dizer que os pronomes masculinos têm uma contribuição positiva e os pronomes femininos têm uma contribuição negativa. Se essas regras tiverem alta validade, isso significa que elas são verdadeiras em geral e o modelo provavelmente é tendencioso.
O ExSum também pode revelar informações inesperadas sobre o comportamento de um modelo. Por exemplo, ao avaliar o classificador de resenhas de filmes, os pesquisadores ficaram surpresos ao descobrir que palavras negativas tendem a ter contribuições mais pontuais e mais nítidas para as decisões do modelo do que palavras positivas. Isso pode ser devido ao fato de os redatores tentarem ser educados e menos contundentes ao criticar um filme, explica Zhou.
“Para realmente confirmar seu entendimento, você precisa avaliar essas alegações com muito mais rigor em muitos casos. Esse tipo de entendimento nesse nível refinado, até onde sabemos, nunca foi descoberto em trabalhos anteriores”, diz ele.
“Passar das explicações locais para a compreensão global era uma grande lacuna na literatura. O ExSum é um bom primeiro passo para preencher essa lacuna”, acrescenta Ribeiro.
Estendendo o quadro
No futuro, Zhou espera desenvolver esse trabalho estendendo a noção de compreensibilidade para outros critérios e formas de explicação, como explicações contrafactuais (que indicam como modificar uma entrada para alterar a previsão do modelo). Por enquanto, eles se concentraram nos métodos de atribuição de recursos, que descrevem os recursos individuais que um modelo usou para tomar uma decisão (como as palavras em uma resenha de filme).
Além disso, ele deseja aprimorar ainda mais a estrutura e a interface do usuário para que as pessoas possam criar regras mais rapidamente. As regras de escrita podem exigir horas de envolvimento humano – e algum nível de envolvimento humano é crucial porque os humanos devem ser capazes de entender as explicações – mas a assistência da IA pode agilizar o processo.
Enquanto pondera sobre o futuro do ExSum, Zhou espera que o trabalho deles destaque a necessidade de mudar a maneira como os pesquisadores pensam sobre as explicações do modelo de aprendizado de máquina.
“Antes deste trabalho, se você tiver uma explicação local correta, está feito. Você alcançou o santo graal de explicar seu modelo. Estamos propondo essa dimensão adicional para garantir que essas explicações sejam compreensíveis. A compreensibilidade precisa ser outra métrica para avaliar nossas explicações”, diz Zhou.
Esta pesquisa é apoiada, em parte, pela National Science Foundation.
Publicado em 09/05/2022 09h19
Artigo original:
Estudo original: