



Os pesquisadores descobriram uma maneira de tornar as vozes geradas por IA, como assistentes pessoais digitais, mais expressivas, com um mínimo de treinamento. O método, que traduz texto em fala, também pode ser aplicado a vozes que nunca fizeram parte do conjunto de treinamento do sistema.
A equipe de cientistas da computação e engenheiros elétricos da Universidade da Califórnia em San Diego apresentou seu trabalho na conferência ACML 2021, que ocorreu online recentemente.
Além de assistentes pessoais para smartphones, casas e carros, o método pode ajudar a melhorar a narração em filmes animados, tradução automática de fala em vários idiomas e muito mais. O método também pode ajudar a criar interfaces de fala personalizadas que capacitam indivíduos que perderam a capacidade de falar, semelhante à voz computadorizada que Stephen Hawking costumava comunicar, mas muito mais expressiva.
“Temos trabalhado nessa área por um longo período de tempo”, disse Shehzeen Hussain, um Ph.D. estudante da Escola de Engenharia da UC San Diego Jacobs e um dos principais autores do artigo. “Queríamos olhar para o desafio de não apenas sintetizar a fala, mas de adicionar um significado expressivo a essa fala.”
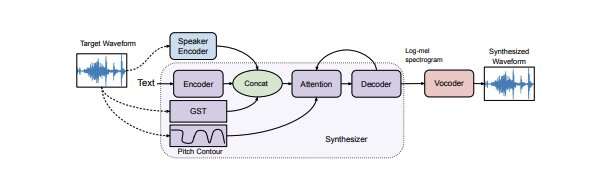
Os métodos existentes ficam aquém deste trabalho de duas maneiras. Alguns sistemas podem sintetizar fala expressiva para um falante específico usando várias horas de dados de treinamento para esse falante. Outros podem sintetizar a fala a partir de apenas alguns minutos de dados de fala de um locutor nunca antes encontrado; mas eles não são capazes de gerar fala expressiva e apenas traduzir texto em fala. Por outro lado, o método desenvolvido pela equipe da UC San Diego é o único que pode gerar, com o mínimo de treinamento, uma fala expressiva para um sujeito que não fez parte de seu conjunto de treinamento.
Os pesquisadores sinalizaram o tom e o ritmo da fala em amostras de treinamento, como um substituto para a emoção. Isso permitiu que seu sistema de clonagem gerasse uma fala expressiva com o mínimo de treinamento, mesmo para vozes que nunca havia encontrado antes.
“Demonstramos que nosso modelo proposto pode fazer com que uma nova voz expresse, emote, cante ou copie o estilo de uma dada fala de referência”, escrevem os pesquisadores.
Seu método pode aprender a fala diretamente do texto; reconstruir uma amostra de fala de um falante alvo; e transferir o tom e o ritmo da fala de um alto-falante expressivo diferente para a fala clonada para o alto-falante alvo.
A equipe está ciente de que seu trabalho pode ser usado para tornar vídeos e clipes de áudio deepfake mais precisos e persuasivos. Como resultado, eles planejam liberar seu código com uma marca d’água que identificará a fala criada por seu método como clonada.
“A clonagem de voz expressiva se tornaria uma ameaça se você pudesse fazer entonações naturais”, disse Paarth Neekhara, o outro autor principal do artigo e Ph.D. estudante de Ciência da Computação na Escola Jacobs. “O desafio mais importante a ser enfrentado é a detecção dessas mídias e vamos nos concentrar nisso a seguir.”
O método em si ainda precisa ser aprimorado. É voltado para falantes de inglês e luta com falantes com um sotaque forte.
Publicado em 07/01/2022 00h18
Artigo original:
Estudo original: