


A inteligência artificial (IA) pode ser treinada para reconhecer se uma imagem de tecido contém um tumor. No entanto, exatamente como ele toma sua decisão permaneceu um mistério até agora. Uma equipe do Centro de Pesquisa para Diagnóstico de Proteínas (PRODI) da Ruhr-Universität Bochum está desenvolvendo uma nova abordagem que tornará a decisão de uma IA transparente e, portanto, confiável. Os pesquisadores liderados pelo professor Axel Mosig descrevem a abordagem na revista Medical Image Analysis.
Para o estudo, o cientista de bioinformática Axel Mosig colaborou com a professora Andrea Tannapfel, chefe do Instituto de Patologia, a oncologista professora Anke Reinacher-Schick do Hospital St. Josef da Ruhr-Universität e o biofísico e diretor fundador do PRODI, professor Klaus Gerwert. O grupo desenvolveu uma rede neural, ou seja, uma IA, que pode classificar se uma amostra de tecido contém tumor ou não. Para esse fim, eles alimentaram a IA com um grande número de imagens microscópicas de tecidos, algumas das quais continham tumores, enquanto outras estavam livres de tumores.
“As redes neurais são inicialmente uma caixa preta: não está claro quais recursos de identificação uma rede aprende com os dados de treinamento”, explica Axel Mosig. Ao contrário dos especialistas humanos, eles não têm a capacidade de explicar suas decisões. “No entanto, para aplicações médicas em particular, é importante que a IA seja capaz de explicar e, portanto, confiável”, acrescenta o cientista de bioinformática David Schuhmacher, que colaborou no estudo.
A IA é baseada em hipóteses falsificáveis
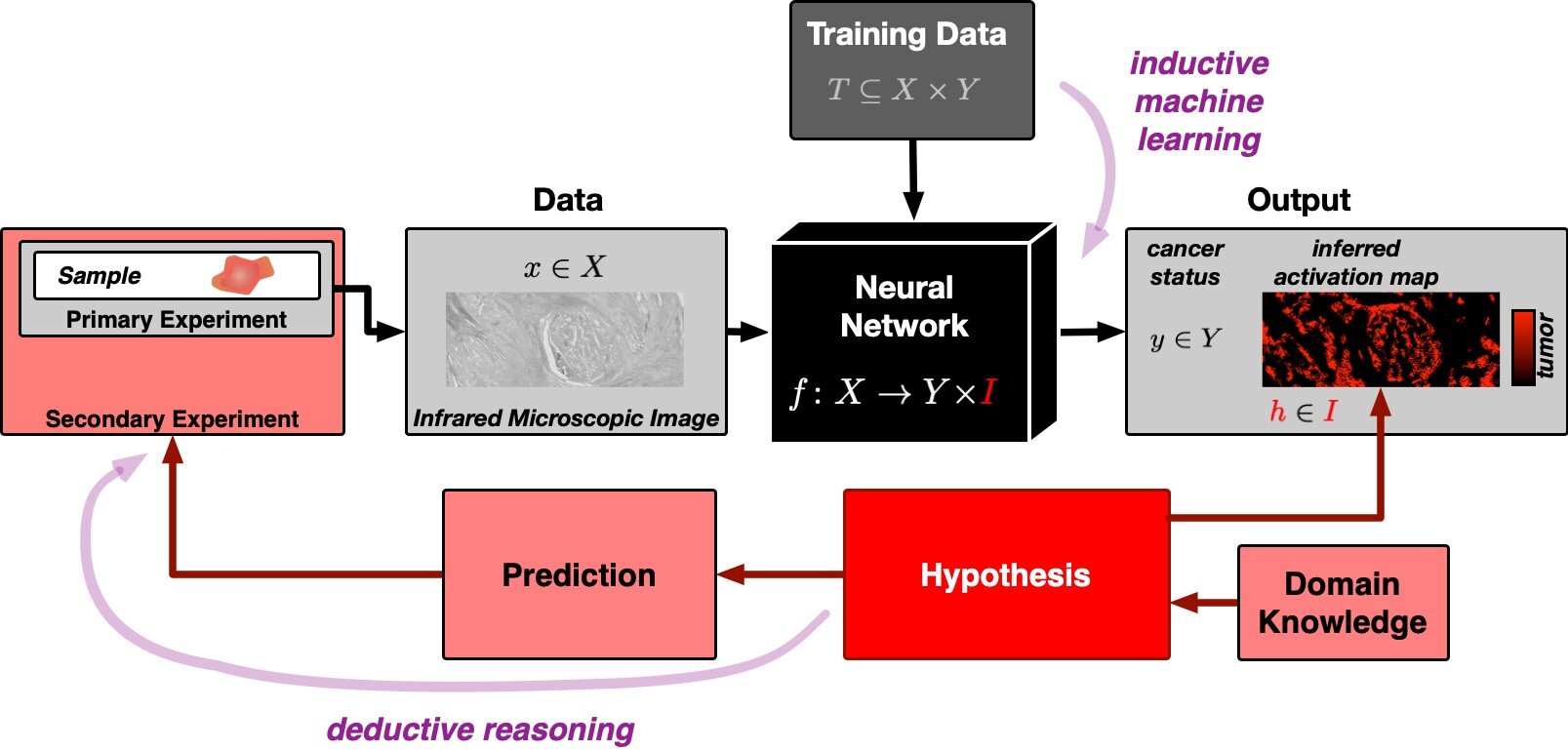
A IA explicável da equipe de Bochum é, portanto, baseada no único tipo de declarações significativas conhecidas pela ciência: em hipóteses falsificáveis. Se uma hipótese é falsa, esse fato deve ser demonstrável por meio de um experimento. A inteligência artificial geralmente segue o princípio do raciocínio indutivo: usando observações concretas, ou seja, os dados de treinamento, a IA cria um modelo geral com base no qual avalia todas as outras observações.
O problema subjacente foi descrito pelo filósofo David Hume há 250 anos e pode ser facilmente ilustrado: não importa quantos cisnes brancos observemos, nunca poderíamos concluir com esses dados que todos os cisnes são brancos e que nenhum cisne negro existe. A ciência, portanto, faz uso da chamada lógica dedutiva. Nesta abordagem, uma hipótese geral é o ponto de partida. Por exemplo, a hipótese de que todos os cisnes são brancos é falsificada quando um cisne negro é visto.

O mapa de ativação mostra onde o tumor é detectado
“À primeira vista, a IA indutiva e o método científico dedutivo parecem quase incompatíveis”, diz Stephanie Schörner, física que também contribuiu para o estudo. Mas os pesquisadores encontraram um caminho. Sua nova rede neural não apenas fornece uma classificação se uma amostra de tecido contém um tumor ou está livre de tumor, mas também gera um mapa de ativação da imagem microscópica do tecido.
O mapa de ativação é baseado em uma hipótese falseável, a saber, que a ativação derivada da rede neural corresponde exatamente às regiões tumorais da amostra. Métodos moleculares específicos do local podem ser usados para testar essa hipótese.
“Graças às estruturas interdisciplinares do PRODI, temos os melhores pré-requisitos para incorporar a abordagem baseada em hipóteses no desenvolvimento de biomarcadores confiáveis AI no futuro, por exemplo, para poder distinguir entre certos subtipos de tumores relevantes para a terapia”, conclui Axel Mosig.
Publicado em 04/09/2022 22h14
Artigo original:
Estudo original: