



Para operar de forma autônoma em vários ambientes desconhecidos e completar missões com sucesso, os robôs móveis devem ser capazes de se adaptar às mudanças em seus arredores. Os sistemas visuais de ensino e repetição (VT&R) são uma classe promissora de abordagens para treinar robôs para navegar adaptativamente em ambientes.
Como o próprio nome sugere, os sistemas VT&R são baseados em duas etapas principais: as etapas de ensino e repetição. Durante a etapa de ensino, os sistemas aprendem com demonstrações de caminhos percorridos por operadores humanos. Posteriormente, durante a etapa de repetição, os robôs tentam replicar o que os humanos fizeram na demonstração, percorrendo o mesmo caminho de forma autônoma e consistente.
Pesquisadores do Oxford Robotics Institute desenvolveram recentemente um novo controlador que pode ajudar a aprimorar os sistemas VT&R. Sua abordagem, apresentada em um artigo publicado no IEEE Robotics and Automation Letters, pode ajudar a desenvolver robôs que são melhores para navegar em ambientes desconhecidos.
“O artigo recente faz parte do nosso trabalho sobre navegação VT&R”, disse Matias Mattamala, um dos autores, ao TechXplore. “Isso é útil para implantar robôs rapidamente para inspecionar novos lugares e coletar dados sem ter que construir um mapa preciso do ambiente. Em nosso trabalho anterior, demonstramos robustez a oclusões visuais alternando entre diferentes câmeras no robô, como quando alguém está passando.”
Em seus estudos anteriores, Mattamala e seus colegas conseguiram treinar modelos para acessar diferentes câmeras em um robô em momentos diferentes, usando dados coletados durante demonstrações humanas. Apesar dessa conquista notável, seus modelos não permitiram que os robôs evitassem ativamente obstáculos potenciais em seus arredores enquanto replicavam a trajetória demonstrada por agentes humanos.
“Começamos a trabalhar nessa ‘camada de segurança’ há algum tempo e nosso artigo recente apresenta-a totalmente funcional“, explicou Mattamala. “Nosso controlador é baseado em uma abordagem recente desenvolvida pela Nvidia chamada Riemannian Motion Policies (RMP).”
O controlador desenvolvido pelos pesquisadores se assemelha em parte a controladores de campo em potencial, ferramentas que permitem aos robôs calcular uma combinação de diferentes forças, como forças de atração (ou seja, aquelas que os impulsionam para completar um objetivo) e forças de repulsão (ou seja, aquelas que os ajudam a ficar longe de obstáculos), para finalmente determinar em que direção seguir. A abordagem RMP da Nvidia, no entanto, leva seu controlador um passo adiante, pois introduz pesos dinâmicos (chamados de métricas) que alavancam essas forças de maneiras diferentes, dependendo do estado da o robô.
“Por exemplo, você não precisa evitar obstáculos sempre, mas apenas quando estiver perto deles ou apontando na direção deles”, explicou Mattamala. “Dessa forma, você pode evitar algumas situações em que as forças de atração e reação se cancelam.”
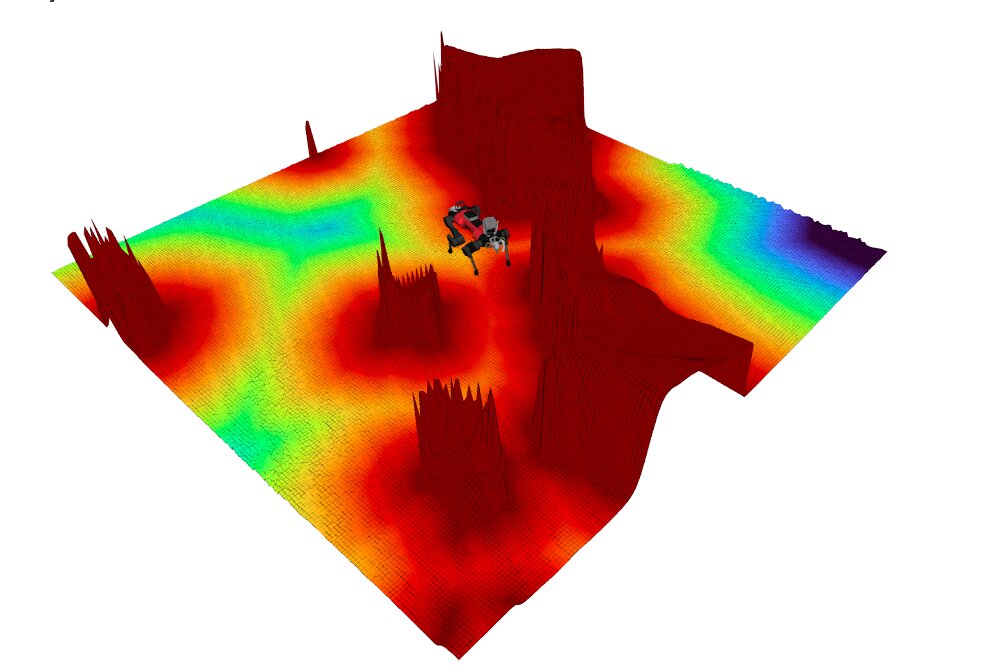
As forças de interação processadas pelo controlador da equipe são computadas a partir de um mapa local que é gerado em tempo real e se adapta à medida que um robô se move em seu ambiente circundante. Ao analisar este mapa local, o sistema pode gerar campos que são fáceis de interpretar e podem ser usados como dados para aprimorar as habilidades de navegação de um robô. Isso inclui um campo de distância sinalizado (SDF), que caracteriza os obstáculos, e um campo de distância do geodisco (GDF), que transmite a distância mais próxima de um objetivo ou local de destino. Ao processar esses campos, o controlador considera o fato de que há uma certa quantidade de espaço no ambiente circundante que o robô não pode se mover ou atravessar.
“Em nosso estudo, fomos capazes de explorar novas técnicas de controle, como RMP, que até agora só foram aplicadas a robôs manipuladores ou pequenos robôs com rodas”, disse Mattamala. “Além disso, implantamos nosso controlador no quadrúpede ANYmal da ANYbotics e realizamos experimentos de circuito fechado em uma mina desativada, o que foi bastante empolgante de testar”.

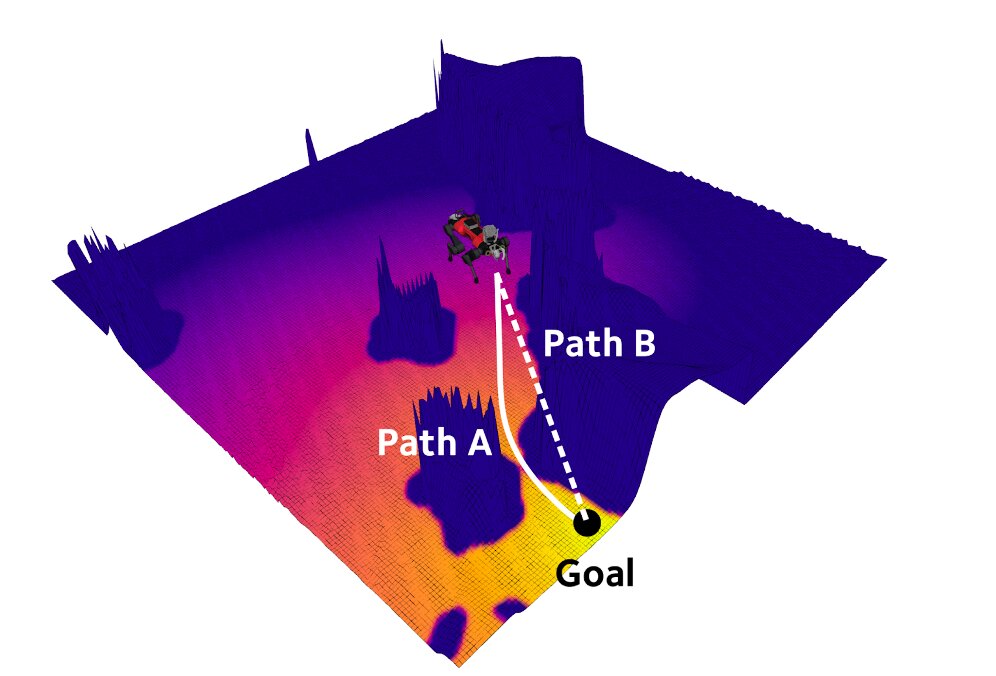
Em contraste com outras abordagens propostas anteriormente, o controlador criado por Mattamala e seus colegas é intrinsecamente reativo, pois não exige que robôs e desenvolvedores planejem com antecedência e prevejam os obstáculos que um robô encontrará em um ambiente específico. Curiosamente, em suas avaliações, a equipe descobriu que, usando melhores representações do ambiente para gerar forças de atração e reação, eles poderiam alcançar resultados semelhantes aos alcançados por modelos que planejam missões com antecedência.
“Por exemplo, colocamos alguns obstáculos bloqueando o caminho de referência e o robô conseguiu dar a volta sem planejamento”, explicou Mattamala. “Também estendemos nosso sistema VT&R para trabalhar com câmeras olho de peixe, como o equipamento Sevensense Alphasense que usamos em nossos experimentos. Alcançamos resultados comparáveis aos experimentos anteriores com câmeras Realsense, que demonstraram a flexibilidade do nosso sistema.”

Até agora, os pesquisadores testaram seu controlador em uma série de espaços internos desordenados e em uma mina subterrânea. Nesses experimentos iniciais, seu sistema alcançou resultados muito promissores, sugerindo que em breve poderia ajudar a melhorar as capacidades de navegação de robôs móveis existentes e recém-desenvolvidos. Notavelmente, o controlador pode ser aplicado a uma variedade de sistemas, pois requer apenas um mapa local gerado usando dados coletados por câmeras de profundidade ou tecnologia LiDAR.

Em seus próximos estudos, Mattamala e seus colegas planejam aplicar e testar seu controlador em outros robôs desenvolvidos em seu laboratório. Além disso, eles gostariam de avaliar seu desempenho em uma gama mais ampla de ambientes dinâmicos do mundo real.
“Nosso trabalho futuro considera estender nosso sistema VT&R para alcançar a navegação visual de longo prazo de robôs com pernas em ambientes industriais e naturais”, explicou Mattamala. “Isso requer (1) melhores sistemas de localização visual, uma vez que mudanças drásticas de aparência devido à iluminação ou condições climáticas desafiarão nosso sistema atual, e (2) melhores controladores de caminhada para obter uma navegação confiável em terrenos acidentados, que devem interagir com o alto nível Imagine ensinar o robô a percorrer trilhas na floresta ou caminhar ao longo de uma trilha de montanha e, em seguida, repetir a trajetória de forma autônoma, não importa o terreno ou o clima – é isso que pretendemos alcançar.”
Publicado em 08/02/2022 21h43
Artigo original:
Estudo original: