


Os dispositivos Edge AI, sistemas que combinam inteligência artificial (AI) e técnicas de edge computing, estão se tornando uma parte essencial do ecossistema da Internet das Coisas (IoT) em rápido crescimento. Esses dispositivos incluem alto-falantes inteligentes, telefones inteligentes, robôs, carros autônomos, drones e câmeras de vigilância com processamento de dados.
Embora essas tecnologias tenham se tornado cada vez mais avançadas nos últimos anos, a maioria delas exibe eficiências de energia limitadas, precisão de inferência e vida útil da bateria. As arquiteturas de computação não volátil na memória (nvCIM), uma classe emergente de abordagens que minimizam a movimentação de dados entre processadores e componentes de memória, podem ajudar a reduzir significativamente a latência e o consumo de energia associados a cálculos complexos de IA.
Pesquisadores da Taiwan Semiconductor Manufacturing Company (TSMC) desenvolveram recentemente uma nova abordagem nvCIM de quatro megabits (4Mb) que pode ajudar a melhorar o desempenho geral dos dispositivos de IA de ponta. Sua arquitetura proposta, apresentada em um artigo publicado na Nature Electronics, combina células de memória com circuitos periféricos baseados na tecnologia de semicondutores de óxido metálico complementar (CMOS).
“A latência de computação e o consumo de energia das redes neurais que operam para aplicativos de IA usando arquiteturas convencionais de computação von Neumann são dominados pelo movimento de dados entre o elemento de processamento e a memória, criando um gargalo de desempenho conhecido como parede de memória”, Meng-Fan Chang, um dos pesquisadores que realizaram o estudo, disse ao TechXplore. “O NvCIM pode ajudar a superar o gargalo da parede de memória para dispositivos de borda de IA alimentados por bateria, permitindo operações analógicas para multiplicação de matriz vetorial, que é a principal operação de computação na rede neural durante o estágio de inferência”.
As arquiteturas NvCIM podem reduzir significativamente a quantidade de dados que são transferidos entre processadores e memórias em dispositivos de borda de IA, principalmente enquanto os dispositivos estão realizando operações de inferência e de inicialização no chip. Isso pode, por sua vez, levar a melhores eficiências energéticas e maior vida útil da bateria.
Chang e seus colegas desenvolvem dispositivos de computação em memória (CIM) há quase 10 anos. Em seus estudos anteriores, eles usaram uma variedade de componentes de memória diferentes, incluindo SRAM, STT-MRAM, PCM, ReRAM e NAND-Flash, para avaliar o desempenho resultante.
“Nos últimos cinco anos, apresentamos 40 trabalhos relacionados ao CIM nas principais conferências de microeletrônica (ISSCC, IEDM e DAC)”, explicou Chang. “Nosso trabalho recente se baseia em nossa pesquisa de longo prazo sobre CIM, que delineou o histórico técnico do design de circuitos de memória, o design de chips em nível de sistema de redes neurais e algoritmos de IA”.
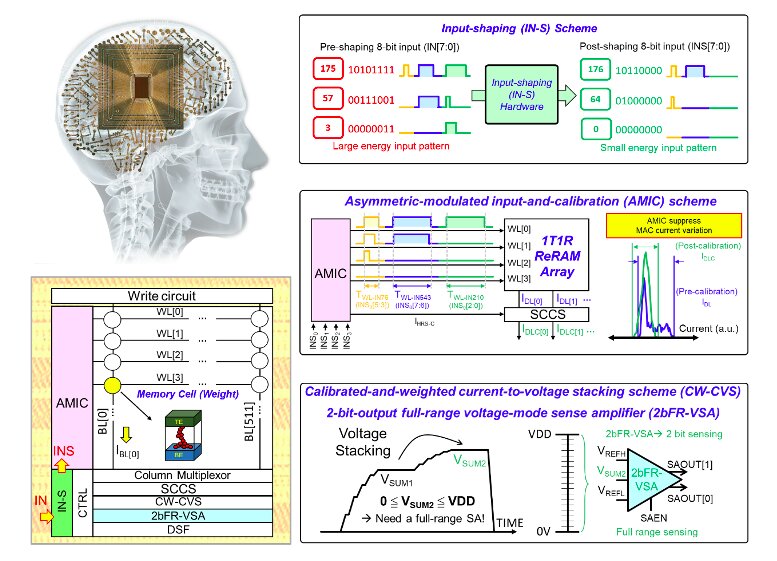
A nova arquitetura nvCIM de 4 Mb criada pelos pesquisadores é baseada em dispositivos de memória de acesso aleatório resistiva (ReRAM) de fundição de 22 nm, também conhecidos como memristores. Notavelmente, Chang e seus colegas descobriram que ele pode realizar operações de produto escalar de alta precisão envolvendo uma entrada de 8 bits, peso de 8 bits e saída de 14 bits com pouca latência e alta eficiência energética.
“Desenvolvemos um circuito de modelagem de entrada baseado em hardware, usando métodos de co-design de software e hardware para melhorar a eficiência energética sem degradar a precisão da inferência no nível do sistema”, disse Chang. “Para reduzir a latência de computação e melhorar a precisão da leitura, desenvolvemos um esquema de entrada e calibração assimétrica (AMIC)”.
Para reduzir a latência de computação do dispositivo, os pesquisadores construíram um circuito de empilhamento de corrente para tensão calibrado e ponderado com uma saída de 2 bits e um amplificador de detecção de modo de tensão de alcance total. Este circuito também garante um bom rendimento de leitura para os bits mais significativos (MSBs), reduzindo a energia geral de leitura da arquitetura.
A arquitetura criada por Chang e seus colegas pode lidar com tarefas complexas de computação em uma variedade de cenários de aplicativos. Além disso, em comparação com outras arquiteturas nvCIM propostas no passado, ele é mais preciso, possui maior throughput computacional e maior capacidade de memória, consome menos energia e possui menor latência computacional.
“Nós também nos concentramos no co-design de software-hardware para melhorar ainda mais o desempenho no nível do chip”, disse Chang. “Dispositivos de borda avançados existentes para aplicativos de IA e Internet das Coisas (AIoT) habilitados para IA geralmente adotam nvCIM para armazenamento de dados desligado para suprimir o consumo de energia no modo de espera e tarefas de computação leves durante a ativação.”
No futuro, a arquitetura desenvolvida por essa equipe de pesquisadores poderá ser usada para melhorar o desempenho e a eficiência energética de diferentes dispositivos de IA de ponta, desde smartphones até sistemas robóticos mais sofisticados. Entre outras coisas, ele pode suportar multiplicações básicas de matrizes de vetores (VMMs) realizadas por vários modelos de redes neurais, incluindo redes neurais de convolução (CNNs) para classificação de imagens ou redes neurais profundas (DNNs).
“Otimização de nível de circuito, novidade de arquitetura nvCIM, melhoria de especificação e desempenho de macro nvCIM são definitivamente os próximos em nosso roteiro”, acrescentou Chang. “O co-design de software-hardware também é um dos nossos futuros tópicos de pesquisa, visamos desenvolver algoritmos de rede neural compatíveis com nvCIM para maximizar ainda mais o desempenho da macro nvCIM. Além disso, nosso objetivo é integrar a macro nvCIM e outros recursos digitais necessários circuitos em um design de sistema de nível de chip para os chips de IA de próxima geração.”
Publicado em 29/01/2022 09h22
Artigo original:
Estudo original: