


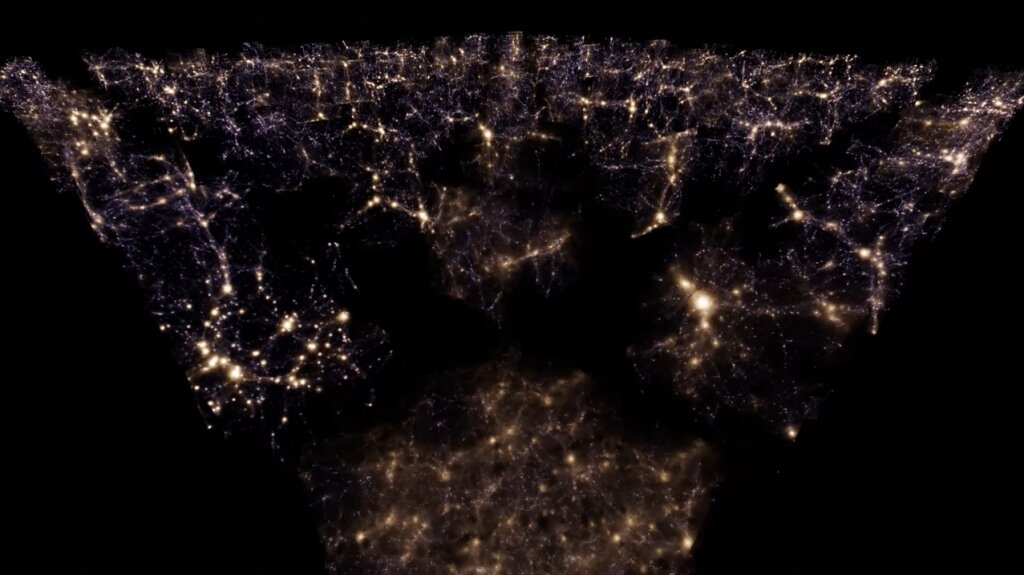
Totalizando 4.233 simulações de universo, milhões de galáxias e 350 terabytes de dados, uma nova versão do projeto CAMELS é um tesouro para cosmologistas. CAMELS – que significa Cosmology and Astrophysics with Machine Learning Simulations – tem como objetivo usar essas simulações para treinar modelos de inteligência artificial para decifrar as propriedades do universo.
Os cientistas já estão usando os dados, que podem ser baixados gratuitamente, para impulsionar novas pesquisas, afirma o co-líder do projeto Francisco Villaescusa-Navarro, um cientista pesquisador do grupo de Simulação e Análise CMB (Fundo Cósmico de Microondas) da Fundação Simons.
Villaescusa-Navarro lidera o projeto com cientistas pesquisadores associados do Centro de Astrofísica Computacional (CCA) do Flatiron Institute, Shy Genel e Daniel Anglés-Alcázar, que também é Professor Associado de Física da UConn.
“O Machine Learning está revolucionando muitas áreas da ciência, mas requer uma grande quantidade de dados para ser explorado”, diz Anglés-Alcázar. “O lançamento de dados públicos CAMELS, com milhares de universos simulados cobrindo uma ampla gama de física plausível, fornecerá às comunidades de formação de galáxias e cosmologia uma oportunidade única de explorar o potencial de novos algoritmos de Machine Learning para resolver uma variedade de problemas.”
A equipe CAMELS gerou as simulações usando código retirado dos projetos IllustrisTNG e Simba. A equipe CAMELS inclui membros de ambos os projetos, com Genel como parte da equipe principal da IllustrisTNG e Anglés-Alcázar na equipe que desenvolveu o Simba.
Cerca de metade das simulações combinam a física do cosmos com a física em escala menor, essencial para a formação de galáxias. Cada simulação é executada com suposições ligeiramente diferentes sobre o universo – por exemplo, em relação a quanto do universo é matéria escura invisível versus a energia escura que separa o cosmos, ou quanta energia buracos negros supermassivos injetam no espaço entre as galáxias.
Os pesquisadores projetaram as simulações para alimentar modelos de Machine Learning, que serão capazes de extrair informações de observações do universo real e observável. Com 4.233 simulações de universo, CAMELS é o maior conjunto de simulações cosmológicas detalhadas projetadas para treinar algoritmos de Machine Learning.
“Os dados permitirão novas descobertas e conectarão a cosmologia com a astrofísica por meio do Machine Learning”, diz Villaescusa-Navarro. “Nunca houve nada semelhante a isso, com tantas simulações de universo.”
O conjunto de dados CAMELS já está alimentando projetos de pesquisa, com uma ampla gama de artigos utilizando os dados nos trabalhos.
Pablo Villanueva-Domingo, da Universidade de Valência, na Espanha, liderou um desses jornais. Ele e seus colegas aproveitaram as simulações do CAMELS para treinar um modelo de inteligência artificial para medir a massa da nossa galáxia, a Via Láctea, mais seu halo de matéria escura circundante e a próxima galáxia de Andrômeda e seu halo. As medições – as primeiras já feitas usando IA – colocam o peso da nossa galáxia em 1 trilhão a 2,6 trilhões de vezes a massa do sol. Essas estimativas estão aproximadamente em linha com aquelas feitas por outros métodos, demonstrando a precisão da abordagem de IA.
Enquanto isso, Villaescusa-Navarro encabeçou um esforço para usar os dados CAMELS para estimar o valor de dois parâmetros que governam as propriedades fundamentais do universo: qual fração do universo é matéria e como a massa é distribuída uniformemente por todo o cosmos. Primeiro, ele e seus colegas usaram CAMELS para gerar mapas como a distribuição de matéria escura, gás e diferentes propriedades das estrelas. Em seguida, usando os mapas, eles treinaram uma ferramenta de Machine Learning chamada rede neural para prever os valores dos dois parâmetros.
“Esse é o mesmo tipo de algoritmo usado para diferenciar um gato e um cachorro a partir dos pixels de uma imagem”, diz Genel, coautor do artigo. “O olho humano não pode determinar quanta matéria escura existe em uma simulação, mas uma rede neural pode fazer isso.”
Os resultados mostraram a promessa de alavancar o CAMELS para estimar com precisão tais parâmetros no futuro com base em novas observações do universo, diz Villaescusa-Navarro.
“É emocionante ver que outras novas descobertas isso possibilitará”, diz ele.
Publicado em 08/01/2022 23h15
Artigo original: