


Dois pesquisadores da Duke University desenvolveram recentemente uma abordagem útil para examinar como certas variáveis são essenciais para aumentar a confiabilidade / precisão dos modelos preditivos. Seu artigo, publicado na Nature Machine Intelligence, poderia ajudar no desenvolvimento de algoritmos de aprendizado de máquina mais confiáveis e com melhor desempenho para uma variedade de aplicações.
“A maioria das pessoas escolhe uma técnica de aprendizado de máquina preditiva e examina quais variáveis são importantes ou relevantes para suas previsões”, disse Jiayun Dong, um dos pesquisadores que realizaram o estudo, ao TechXplore. “E se houvesse dois modelos que tivessem desempenho semelhante, mas usassem variáveis totalmente diferentes? Se fosse esse o caso, um analista poderia cometer um erro e pensar que uma variável é importante, quando na verdade existe um modelo diferente e igualmente bom para que um conjunto totalmente diferente de variáveis é importante. ”
Dong e sua colega Cynthia Rudin introduziram um método que os pesquisadores podem usar para examinar a importância das variáveis para uma variedade de modelos preditivos quase ótimos. Essa abordagem, que eles chamam de “nuvens de importância variável”, poderia ser usada para obter uma melhor compreensão dos modelos de aprendizado de máquina antes de selecionar os mais promissores para concluir uma determinada tarefa.
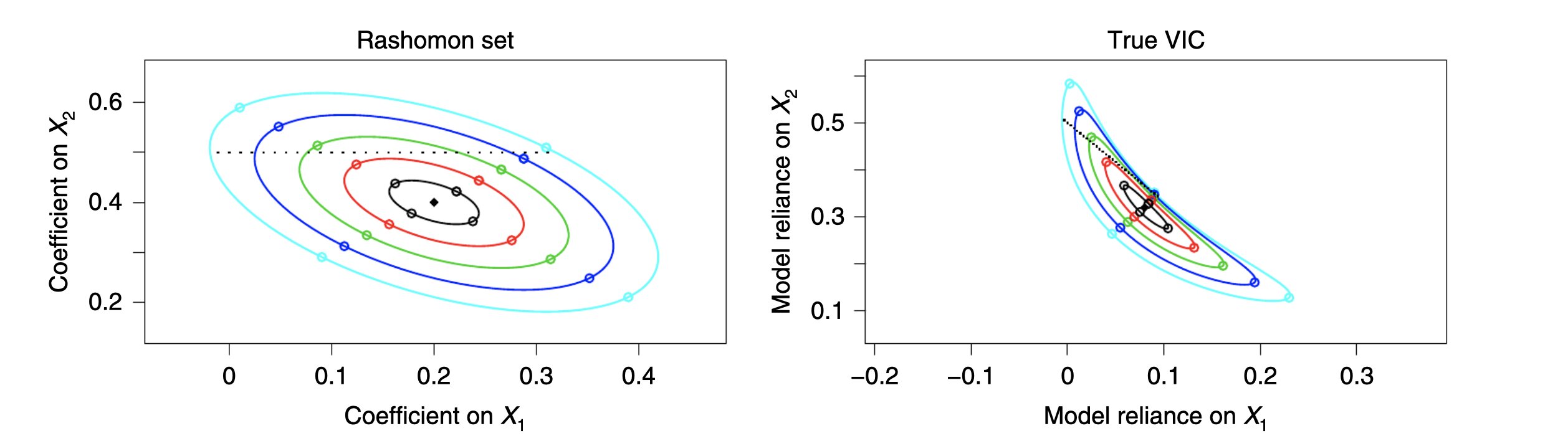
O termo “nuvens de importância variável” vem da ideia de que existem vários modelos (ou seja, toda uma “nuvem” deles) que se pode avaliar em termos de importância variável. Essas nuvens podem ajudar os pesquisadores a identificar variáveis que são importantes e aquelas que não são. Normalmente, a importância de uma variável implica que outra variável é menos importante (ou seja, não orienta tanto as previsões de um determinado modelo).
“Nesse contexto, a nuvem é o conjunto de modelos vistos através das lentes de importância variável”, disse Dong. “Mas vamos discutir como calculá-lo. Para cada modelo preditivo que é quase ótimo (o que significa que é quase tão bom quanto o melhor), calculamos a importância de cada variável para esse modelo. Em seguida, representamos esse modelo como um ponto no espaço de importância variável, onde a localização do ponto representa a importância de suas variáveis. A coleção de tais pontos (um para cada modelo preditivo) é chamada de nuvem de importância variável. ”
A abordagem desenvolvida por Dong e Rudin redireciona as análises para garantir que elas não examinem um único modelo de aprendizado de máquina, mas sim o conjunto de todos os bons modelos preditivos. Quando enumerar todos os bons modelos preditivos é desafiador ou impossível, os pesquisadores usam técnicas de amostragem para adicionar amostras na nuvem ou técnicas de otimização para delinear as bordas da nuvem.
“A forma da nuvem de importância variável transmite informações valiosas sobre a importância das variáveis para a tarefa de previsão; muito mais rica do que abordagens considerando apenas um único modelo”, disse Dong. ?Além de visualizar o limite superior e inferior da importância de cada variável, a nuvem de importância da variável também mostra a correlação entre a importância das diferentes variáveis. Ou seja, revela se uma variável se torna menos importante quando outra variável se torna mais importante, e vice versa.”
Nuvens de importância variável revelam muito mais informações sobre o valor preditivo de diferentes variáveis do que abordagens de avaliação de modelo anteriores com base em análises padrão. Na verdade, os métodos de análise existentes negligenciariam todas as informações contidas na nuvem, exceto por um único ponto correspondente a um modelo individual de interesse.
“A principal implicação de nossas descobertas é que devemos ter cuidado para não interpretar a importância de uma variável para um modelo como sua importância geral”, disse Dong. “Em nosso artigo, essa nota de advertência é transmitida por meio de um exemplo relacionado à previsão de reincidência criminal, onde os modelos podem ou não fazer previsões baseadas explicitamente na raça, dependendo de quanto valorizam outras variáveis, como idade e número de crimes anteriores (todos três estão correlacionados com raça devido ao racismo sistêmico na sociedade). ”
No geral, o estudo realizado por Dong e Rudin mostra que os pesquisadores que desenvolvem ou usam técnicas de aprendizado de máquina devem ser cuidadosos ao afirmar que um único modelo é valioso para uma determinada aplicação, pois pode haver outros modelos que podem atingir desempenho comparável ou melhor, mas com foco em variáveis mais consequentes. Nuvens de importância variável logo poderão ser aplicadas a uma variedade de campos, abrindo caminho para um melhor entendimento e uso de modelos de aprendizado de máquina preditivos.
“Demos apenas alguns exemplos de previsão de reincidência e visão computacional, mas esperamos que outros os usem para considerar cuidadosamente a incerteza de importância variável para seus próprios modelos”, disse Dong. ?Em termos de pesquisa, apresentamos uma maneira de visualizar o VIC (por meio de projeções em duas variáveis), mas há muitas questões científicas interessantes sobre como fazer amostragem para melhor aproximar o VIC para casos de alta dimensão, e outras questões
Publicado em 15/01/2021 19h23
Artigo original:
Estudo original: